「仕事ではじめる機械学習」のUplift Modelingのコードを写経してみた
仕事ではじめる機械学習第9章のUplift Modelingのコードを写経してみた。
使用したnotebookはこちら。
Uplift Modelingとは
ある施策をおこなうと効果があるかどうかを見極める方法の1つにA/Bテストがある。 A/Bテストでは、母集団をランダムにtreatment groupとcontrol groupに分割してtreatment groupにのみ施策をおこない、 treatment groupとcontrol group間で効果に差があるかどうかを確認することで その施策をおこなうべきかどうかを判断する。
ダイレクトメールを送ることでWebサイトへの訪問を促す施策を例にとると、 treatment groupにのみメールを送付し、treatment groupに属する顧客の反応率がcontrol groupに属する顧客のそれよりも高かった場合、 メール送付という施策には効果があることがわかる。
しかしUplift Modelingを使うと単にtreatment groupとcontrol groupに差があったかどうかだけではなく、 施策をおこなうことで施策をおこなわなかったときと比べて 反応率がどれだけ上がるのか(これがuplift)を顧客ごとに推定することができ、 反応率が大きく上昇するであろう顧客のみに施策を適用することも可能となる。
使用するデータ
MineThatData E-Mail Analytics And Data Mining Challenge datasetを使用する。
このデータには、直近12ヶ月以内に商品を購入したことがある顧客をランダムに3分割し、
- 男性向けのメールを送る
- 女性向けのメールを送る
- 何もしない
という施策をおこなったときに、顧客が次の2週間以内に
- Webサイトを訪問したか
- 商品を購入したか
- 商品を購入した人は何ドルいくら使ったのか
などの情報が記録されている。
ここでは、Webサイトへの再訪をコンバージョン(以下CV)として、
男性向けのメールを送るべきなのか女性向けのメールを送るべきなのかをUplift Modelingにより推定する。
準備・前処理
ローカルにダウンロードしてデータを読み込む。
csv_path = '~/downloads/kevin_hillstrom_minethatdata_e-mailanalytics_dataminingchallenge_2008.03.20.csv'
df = pd.read_csv(csv_path)
まずメールを送らなかったグループを除外する。
mailed_df = df.query("segment != 'No E-Mail'")
mailed_df.reset_index(drop=True, inplace=True)
次に、カテゴリ変数であるzip_codeとchannelはダミー変数化してそれぞれ2次元にマッピングし、
recency, history, mens, womensと合わせて特徴量として使用する。
dummied_df = pd.get_dummies(
mailed_df[['zip_code', 'channel']], prefix_sep='=', drop_first=True)
features_to_use = ('recency', 'history', 'mens', 'womens', 'newbie')
fv_df = mailed_df.filter(features_to_use).join(dummied_df)
学習
男性向けメールを送った顧客をtreatment group、女性向けメールを送った顧客をcontrol groupとする。
is_treat = mailed_df['segment'] == 'Mens E-Mail'
is_visit = mailed_df['visit'] == 1
データをtraining setとtest setに分割する。
tr_fv_df, te_fv_df, tr_is_visit, te_is_visit, tr_is_treat, te_is_treat = \
train_test_split(fv_df, is_visit, is_treat, test_size=0.5, random_state=42)
tr_fv_df.reset_index(drop=True, inplace=True)
te_fv_df.reset_index(drop=True, inplace=True)
tr_is_visit.reset_index(drop=True, inplace=True)
te_is_visit.reset_index(drop=True, inplace=True)
tr_is_treat.reset_index(drop=True, inplace=True)
te_is_treat.reset_index(drop=True, inplace=True)
treatment group, control groupそれぞれについてロジスティック回帰を使って
メール送付によって顧客がWebサイトを再訪するかどうかを予測するモデルを作成する。
tr_fv_df_treat = tr_fv_df[tr_is_treat]
tr_fv_df_control = tr_fv_df[tr_is_treat == False]
tr_is_visit_treat = tr_is_visit[tr_is_treat]
tr_is_visit_control = tr_is_visit[tr_is_treat == False]
treat_model = LogisticRegression(C=0.01)
control_model = LogisticRegression(C=0.01)
treat_model.fit(tr_fv_df_treat, tr_is_visit_treat)
control_model.fit(tr_fv_df_control, tr_is_visit_control)
スコアリングによる可視化
各顧客について、Uplift Modelingによるスコアを計算する。Uplift Modelingのスコアは、
- treatment groupのモデルで予測したCV確率 / control groupのモデルで予測したCV確率
で表される。
スコアの降順に10パーセンタイルごとに顧客を区切り、
treatment group, control groupそれぞれのcvrを表示すると下の図のようになる。
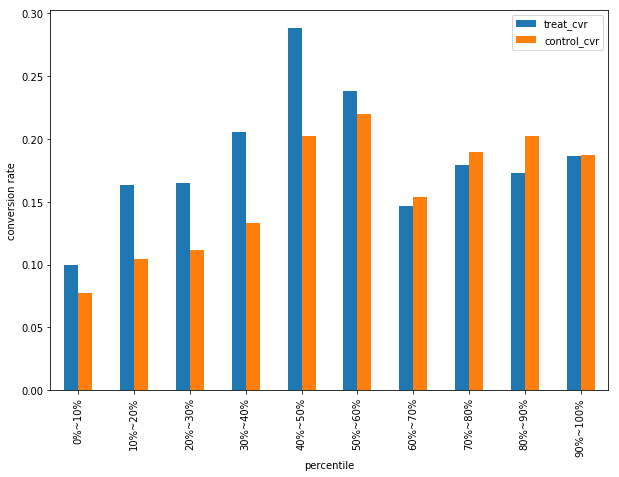
この図から、スコアの上位60%は介入をおこなう(男性向けメールを送付する)ほうが反応率が高くなり、 スコアの下位40%は介入をおこなわない(女性向けメールを送付する)ほうが反応率が高くなることがわかる。
AUUCによる評価
Uplift Modelingの評価にはAUUCが用いられ、AUUCの算出にはliftという指標が用いられる。
liftとは、あるスコアを閾値としたとき、その閾値以上の顧客にのみ介入した場合と
全く介入をおこなわなかった場合とを比較してどれだけCV数が増えるかを表す値である。
横軸をスコアの降順に並べたときの順位とすると、liftは下の図で示すような曲線となり、この曲線とx軸で囲まれた面積が全く介入をおこなわない場合と比較したCV上昇数となる。
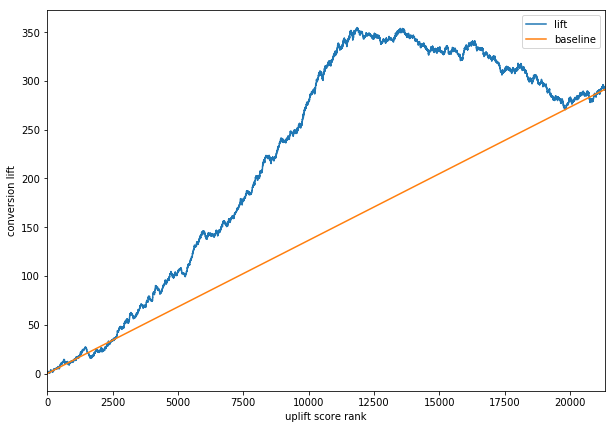
高めのスコアを閾値とした場合、スコア上位の顧客ほど介入したほうがCVに至る確率が増すためlift曲線の左側は正の傾きとなるが、
逆に低めのスコアを閾値とした場合介入しないほうがCVに至る確率が増すためlift曲線の右側は負の傾きとなる。そのため、lift曲線は上に凸の曲線となる。
曲線のピークの位置(図でいうとスコアランク12000番前後)のスコアを閾値としたときが最も効率的な介入のしかたであるといえる。
一方、liftと同様にあるスコアを閾値として、その閾値以上の顧客に対してランダムに介入した場合(スコアが閾値以上であっても介入する顧客と介入しない顧客がいる)と全く介入をおこなわなかった場合とを比較してどれだけCV数が増えるかについて考える。 ランダム介入はデータとして観測していないため、lift曲線の左端と右端を結んだ直線をランダム介入によるCV上昇数の想定値とし、これをbaselineとする (lift曲線とbaseline直線の左端は全く介入をおこなわなかったときの増加分を意味するのでこの2つの左端0で一致する。右端は必ずしも一致しない(はずだ)が、簡単のためlift曲線の左端と右端を結んだ直線としている?)。 ランダム介入によるCV上昇数はこの直線とx軸で囲まれた面積となる。
AUUCとは、スコアが閾値以上の顧客に対して介入する場合とスコアが閾値以上の顧客に対してランダムに介入した場合と比較してどれだけCV数が増えるかを示す値であり、lift曲線とbaseline直線で囲まれた面積にあたる。この面積が大きいほどUplift Modelingの精度が高いといえる。